| Home | Trees | Indices | Help |
|---|
|
|
|
|||
_fail_count = 0
|
|||
_allowed_failures = 10
|
|||
|
Inherited from |
|||
|
|||
|
Inherited from Inherited from Inherited from Inherited from Inherited from Inherited from Inherited from Inherited from |
|||
|
|||
x.__init__(...) initializes x; see help(type(x)) for signature
|
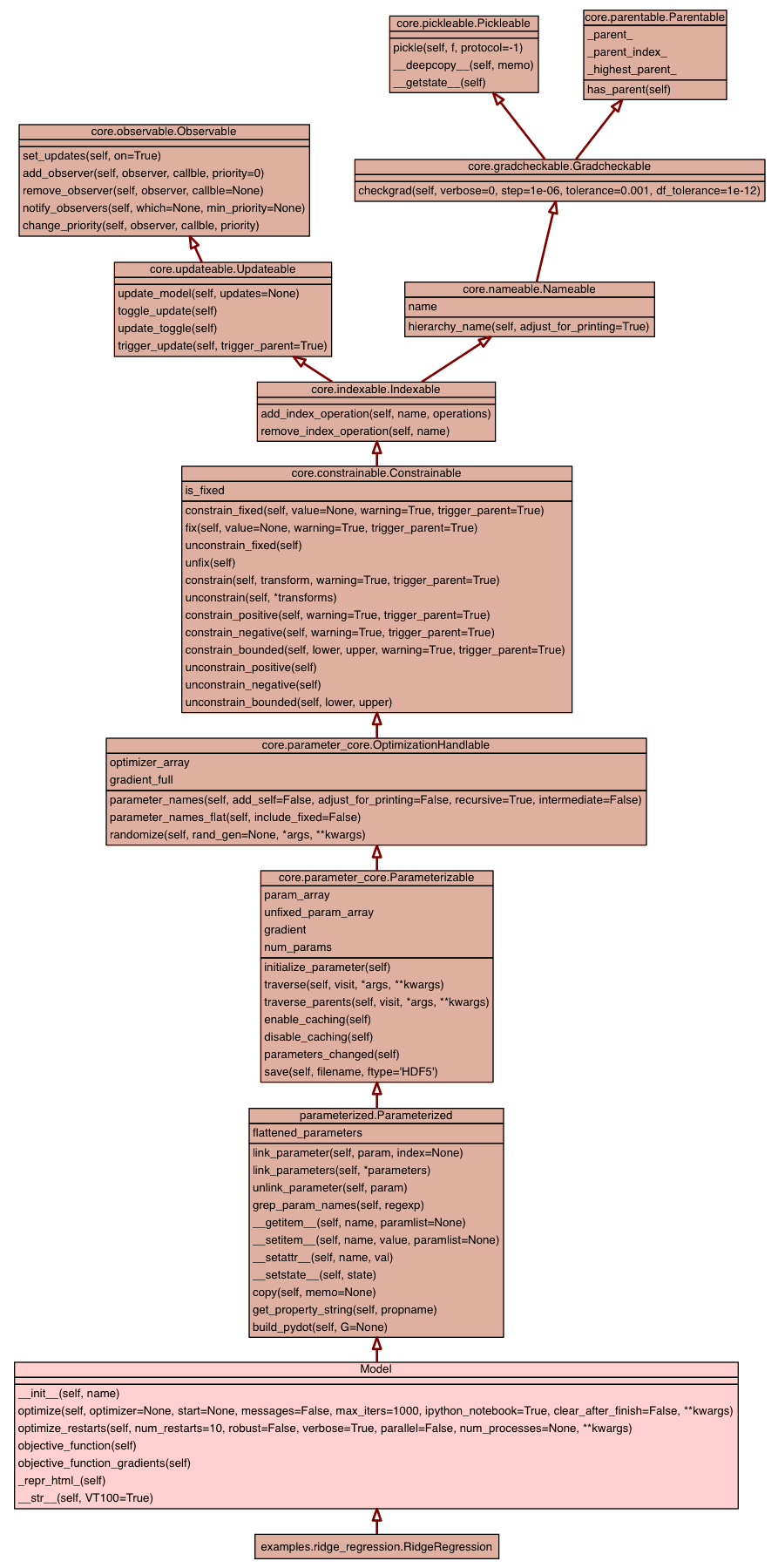
Optimize the model using self.log_likelihood and self.log_likelihood_gradient, as well as self.priors. kwargs are passed to the optimizer. They can be: :param max_iters: maximum number of function evaluations :type max_iters: int :messages: True: Display messages during optimisation, "ipython_notebook": :type messages: bool"string :param optimizer: which optimizer to use (defaults to self.preferred optimizer) :type optimizer: string Valid optimizers are:
|
Perform random restarts of the model, and set the model to the best seen solution. If the robust flag is set, exceptions raised during optimizations will be handled silently. If _all_ runs fail, the model is reset to the existing parameter values. \*\*kwargs are passed to the optimizer. :param num_restarts: number of restarts to use (default 10) :type num_restarts: int :param robust: whether to handle exceptions silently or not (default False) :type robust: bool :param parallel: whether to run each restart as a separate process. It relies on the multiprocessing module. :type parallel: bool :param num_processes: number of workers in the multiprocessing pool :type numprocesses: int :param max_f_eval: maximum number of function evaluations :type max_f_eval: int :param max_iters: maximum number of iterations :type max_iters: int :param messages: whether to display during optimisation :type messages: bool .. note: If num_processes is None, the number of workes in the multiprocessing pool is automatically set to the number of processors on the current machine. |
The objective function for the given algorithm. This function is the true objective, which wants to be minimized. Note that all parameters are already set and in place, so you just need to return the objective function here. For probabilistic models this is the negative log_likelihood (including the MAP prior), so we return it here. If your model is not probabilistic, just return your objective to minimize here! |
The gradients for the objective function for the given algorithm. The gradients are w.r.t. the *negative* objective function, as this framework works with *negative* log-likelihoods as a default. You can find the gradient for the parameters in self.gradient at all times. This is the place, where gradients get stored for parameters. This function is the true objective, which wants to be minimized. Note that all parameters are already set and in place, so you just need to return the gradient here. For probabilistic models this is the gradient of the negative log_likelihood (including the MAP prior), so we return it here. If your model is not probabilistic, just return your *negative* gradient here! |
Gets the gradients from the likelihood and the priors. Failures are handled robustly. The algorithm will try several times to return the gradients, and will raise the original exception if the objective cannot be computed. :param x: the parameters of the model. :type x: np.array |
The objective function passed to the optimizer. It combines the likelihood and the priors. Failures are handled robustly. The algorithm will try several times to return the objective, and will raise the original exception if the objective cannot be computed. :param x: the parameters of the model. :parameter type: np.array |
Check the gradient of the ,odel by comparing to a numerical estimate. If the verbose flag is passed, individual components are tested (and printed) :param verbose: If True, print a "full" checking of each parameter :type verbose: bool :param step: The size of the step around which to linearise the objective :type step: float (default 1e-6) :param tolerance: the tolerance allowed (see note) :type tolerance: float (default 1e-3) Note:- The gradient is considered correct if the ratio of the analytical and numerical gradients is within <tolerance> of unity. The *dF_ratio* indicates the limit of numerical accuracy of numerical gradients. If it is too small, e.g., smaller than 1e-12, the numerical gradients are usually not accurate enough for the tests (shown with blue).
|
Representation of the model in html for notebook display.
|
str(x)
|
| Home | Trees | Indices | Help |
|---|
| Generated by Epydoc 3.0.1 on Tue Jul 4 11:59:46 2017 | http://epydoc.sourceforge.net |