| Home | Trees | Indices | Help |
|---|
|
|
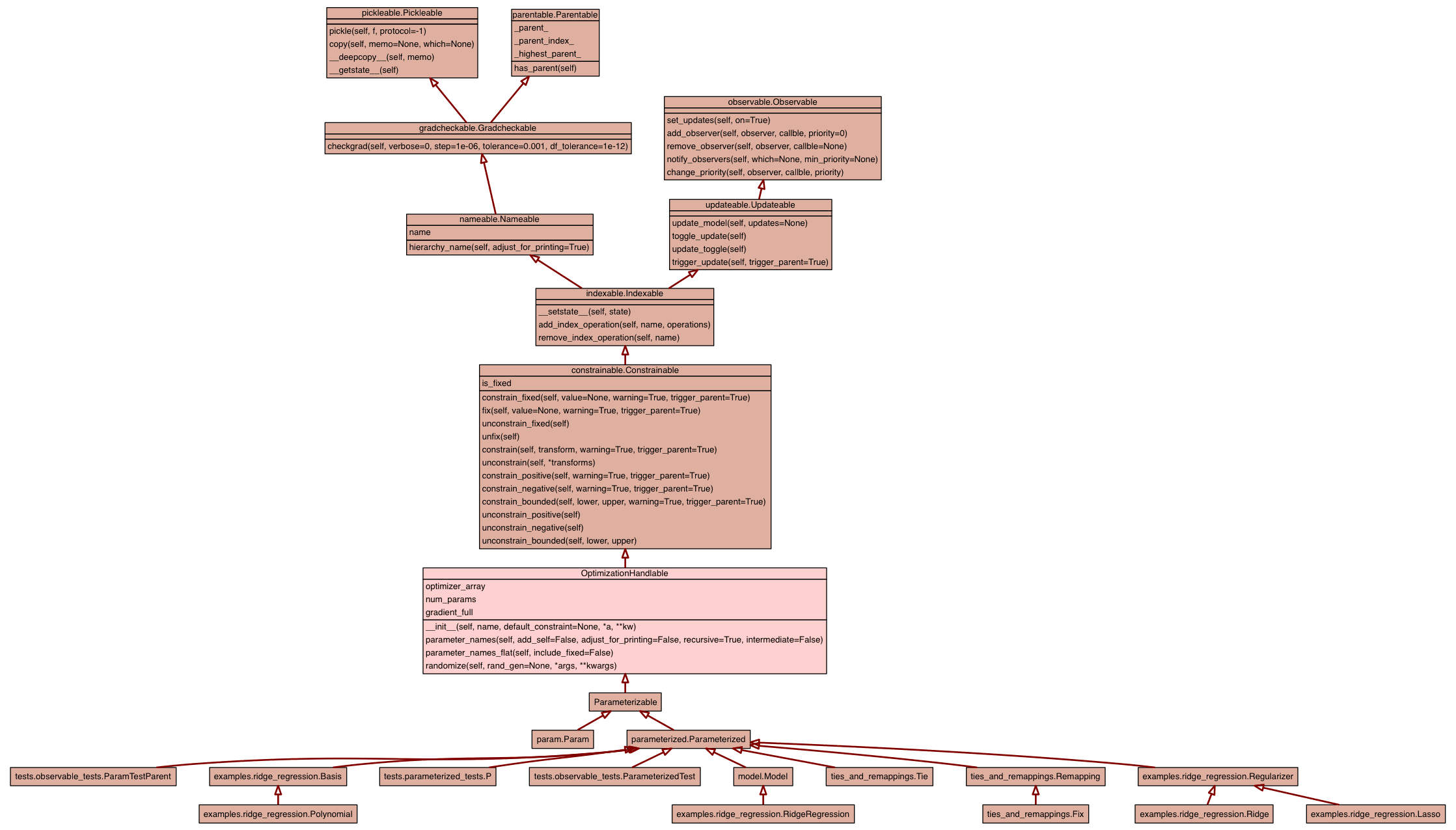
This enables optimization handles on an Object as done in GPy 0.4.
`..._optimizer_copy_transformed`: make sure the transformations and constraints etc are handled
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
Inherited from Inherited from Inherited from Inherited from Inherited from Inherited from Inherited from Inherited from Inherited from Inherited from Inherited from Inherited from Inherited from |
|||
|
|||
|
Inherited from |
|||
|
|||
|
optimizer_array Array for the optimizer to work on. |
|||
|
num_params Return the number of parameters of this parameter_handle. |
|||
|
gradient_full Note to users: This does not return the gradient in the right shape! Use self.gradient for the right gradient array. |
|||
|
Inherited from Inherited from Inherited from Inherited from |
|||
|
|||
x.__init__(...) initializes x; see help(type(x)) for signature
|
First tell all children to update, then update yourself. If trigger_parent is True, we will tell the parent, otherwise not. |
Get the names of all parameters of this model or parameter. It starts
from the parameterized object you are calling this method on.
Note: This does not unravel multidimensional parameters,
use parameter_names_flat to unravel parameters!
:param bool add_self: whether to add the own name in front of names
:param bool adjust_for_printing: whether to call `adjust_name_for_printing` on names
:param bool recursive: whether to traverse through hierarchy and append leaf node names
:param bool intermediate: whether to add intermediate names, that is parameterized objects
|
Return the flattened parameter names for all subsequent parameters
of this parameter. We do not include the name for self here!
If you want the names for fixed parameters as well in this list,
set include_fixed to True.
if not hasattr(obj, 'cache'):
obj.cache = FunctionCacher()
:param bool include_fixed: whether to include fixed names here.
|
Randomize the model. Make this draw from the rand_gen if one exists, else draw random normal(0,1) :param rand_gen: np random number generator which takes args and kwargs :param flaot loc: loc parameter for random number generator :param float scale: scale parameter for random number generator :param args, kwargs: will be passed through to random number generator |
For propagating the param_array and gradient_array. This ensures the in memory view of each subsequent array. 1.) connect param_array of children to self.param_array 2.) tell all children to propagate further |
|
|||
optimizer_arrayArray for the optimizer to work on. This array always lives in the space for the optimizer. Thus, it is untransformed, going from Transformations. Setting this array, will make sure the transformed parameters for this model will be set accordingly. It has to be set with an array, retrieved from this method, as e.g. fixing will resize the array. The optimizer should only interfere with this array, such that transformations are secured.
|
num_paramsReturn the number of parameters of this parameter_handle. Param objects will always return 0.
|
gradient_fullNote to users: This does not return the gradient in the right shape! Use self.gradient for the right gradient array. To work on the gradient array, use this as the gradient handle. This method exists for in memory use of parameters. When trying to access the true gradient array, use this.
|
| Home | Trees | Indices | Help |
|---|
| Generated by Epydoc 3.0.1 on Tue Jul 4 11:59:38 2017 | http://epydoc.sourceforge.net |